 Implementation steps for predicting the appearance of depression
Implementation steps for predicting the appearance of depressionAbstract
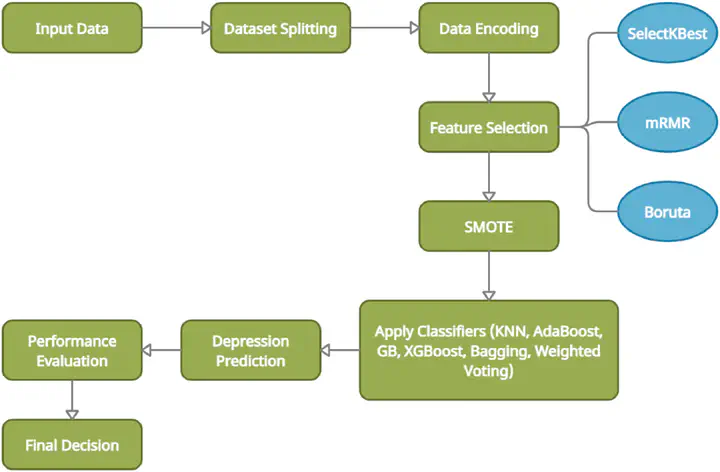
Among all the forms of psychological and mental disorders, depression is the most common form. Nowadays a large number of youths and adults around the world suffer from depression. Depression can cause severe problems in case of failing to detect it at an early stage or failing to ensure the timely counseling of a depressed person. It is one of the major reasons to raise suicidal cases. But ironically, our society still does not want to acknowledge depression as a mental disorder causing a significant number of depressed persons to remain unidentified and untreated. This study has investigated six different machine learning classifiers using various socio-demographic and psychosocial information to detect whether a person is depressed or not. Besides, three different feature selection methods, such as Select K-Best Features (SelectKBest), Minimum Redundancy and Maximum Relevance (mRMR), and Boruta feature selection algorithm have been used for extracting the most relevant features from the dataset. To achieve better accuracy in predicting depression, Synthetic Minority Oversampling Technique (SMOTE) has been used that reduces the class imbalance of the training data. The AdaBoost classifier with the SelectKBest feature selection technique has outperformed all other approaches with an accuracy of 92.56%. Moreover, other evaluation metrics, namely sensitivity, specificity, precision, F1-score, and area under the curve (AUC) of different models have been calculated to identify the most efficient model for predicting depression.
Al Amin Biswas
First Year PhD Student
My research interests include Machine Learning, Deep Learning, Natural Language Processing, AI in Healthcare, Health Informatics, and Human-Computer Interaction.